This article outlines the real failure modes of agentic systems in production, and the infrastructure required to make autonomy and trust coexist at scale.
The Hidden Map Problem
Every agent operates on an internal map of the world—a mental model it constructs on the fly to navigate decisions, tool usage, and problem-solving. The fundamental reliability challenge is that this map is often incomplete or wrong, and we have almost no visibility into how it's constructed.
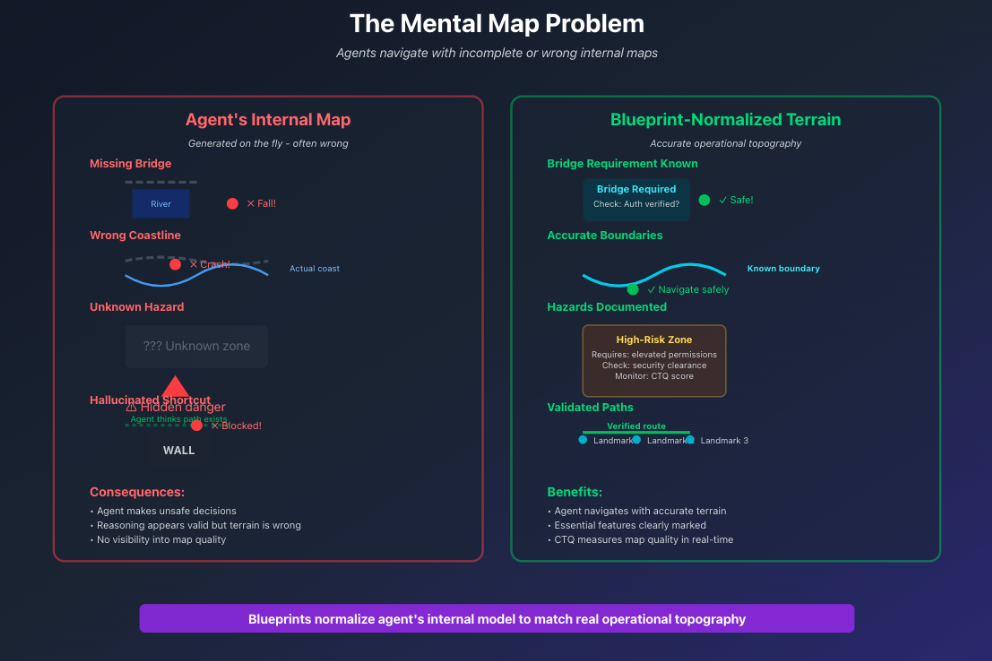
How agents navigate with incomplete internal maps
🎯 The Core Problem
Traditional monitoring gives you logs of what the agent did. But when an agent calls the wrong tool, chains operations incorrectly, or produces an unsafe output, the question isn't "what did it do?"—it's "what was it thinking when it decided to do that?"
You cannot build reliable systems when the core reasoning process is a black box.
The Production Failure Patterns
After observing thousands of agent traces in production, recurring failure patterns emerge. These aren't model bugs; they're structural weaknesses in how agents reason with tools and constraints.

Common tool calling failure patterns in production
Tool Calling Failures
Agents fail with tools in predictable ways:
Missing Preconditions
Calling a payment API before completing identity verification.
Hallucinated Capabilities
Assuming a tool can do more than it actually does.
Skipped Error Handling
No contingency when tools return unexpected data.
Unsafe Chaining
Stacking tools without verifying intermediate states.
Wrong Reasoning, Right Tool
Selecting the correct tool for the wrong reasons.
⚡ The Problem Isn't Tool Availability
It's whether the agent understands what it's doing before it acts. Most tool failures happen because the agent didn't understand the reasoning required, not because the tool itself failed.
Cognitive Drift
Agents don't usually fail catastrophically. They drift:
- Gradually moving from well-understood terrain into high-risk decision spaces
- Exploring possibility spaces that don't align with operational reality
- Building reasoning chains with missing bridges or mis-shaped assumptions
- Accumulating small errors that compound into system failures
Without continuous measurement of reasoning quality, you can't detect this drift until it's too late.
The Scalability Trap
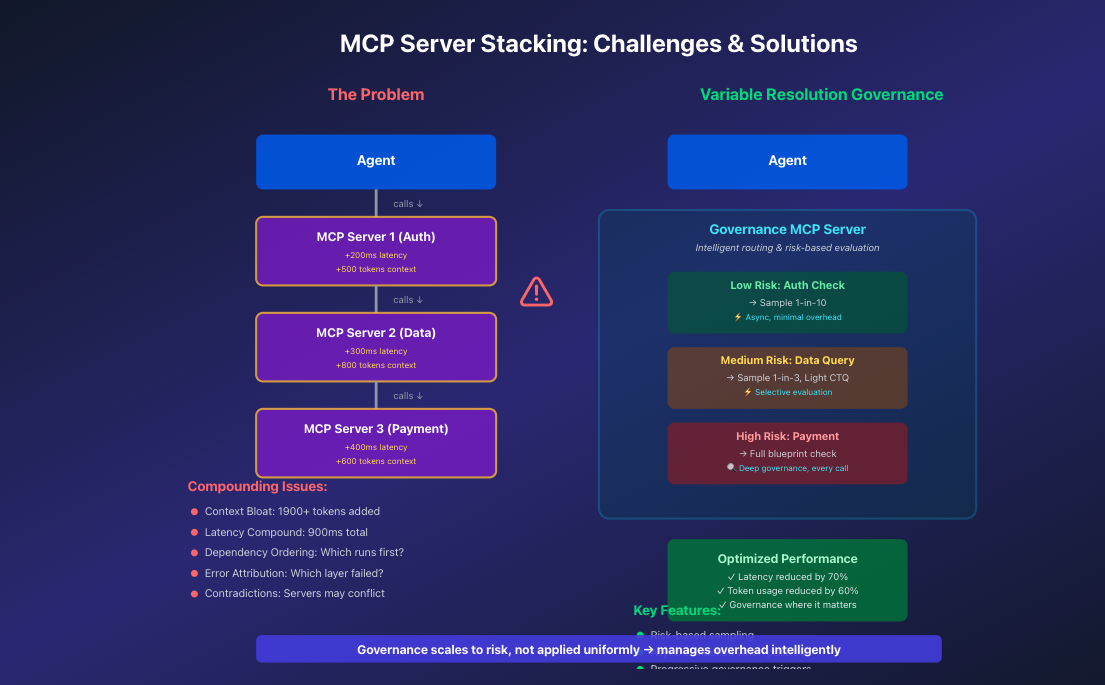
How MCP server stacking creates compounding challenges
As systems grow more complex—multiple agents, stacked MCP servers, distributed tool chains—traditional approaches break. Uniform governance creates uniform overhead. Reliable systems need adaptive infrastructure that scales oversight to actual risk.
A New Category: Operational Agent Reliability
What's needed isn't just better monitoring or stricter controls. It's a new infrastructure layer designed specifically for the unique failure modes of agentic systems.
Core Components of Reliable Agent Infrastructure
1. Blueprints: Mapping the Terrain
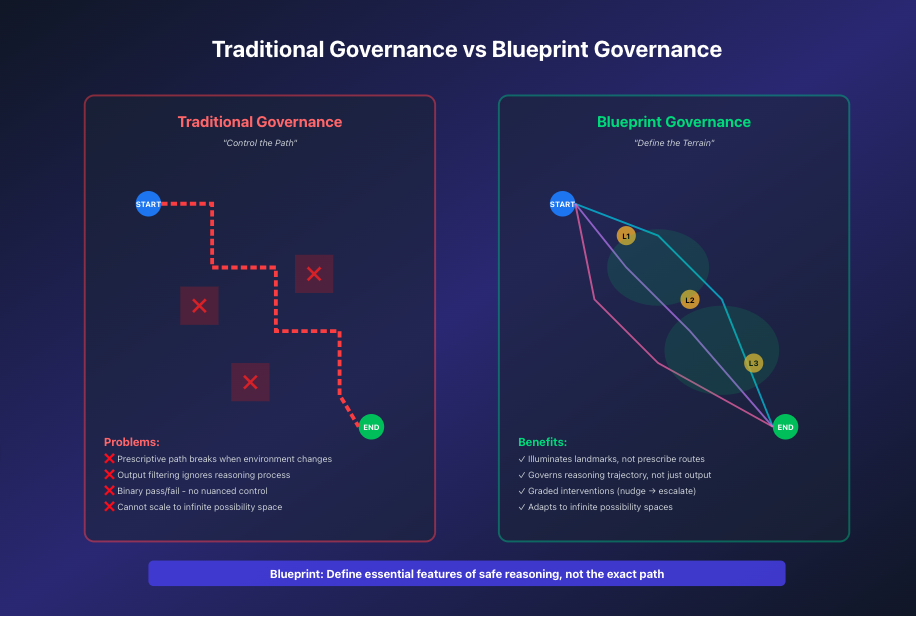
Traditional governance vs. Blueprint-driven governance
Blueprints are deterministic symbolic representations of what safe, complete reasoning looks like for a specific domain or task. They don't prescribe a specific path—they define the terrain the agent must navigate.
💡 The Blueprint Advantage
Traditional approaches try to control the agent's every move. But the moment the environment changes, your prescribed path becomes useless. Instead, Blueprints illuminate the critical landmarks: “You must consider these scenarios. You must verify these preconditions. You must check these intermediate states.”
Blueprint normalization means taking the agent's internal model and ensuring it matches the real operational topography of your domain. It's how you prevent agents from navigating with missing bridges or faulty maps.
2. CTQ: Measuring Reasoning Quality
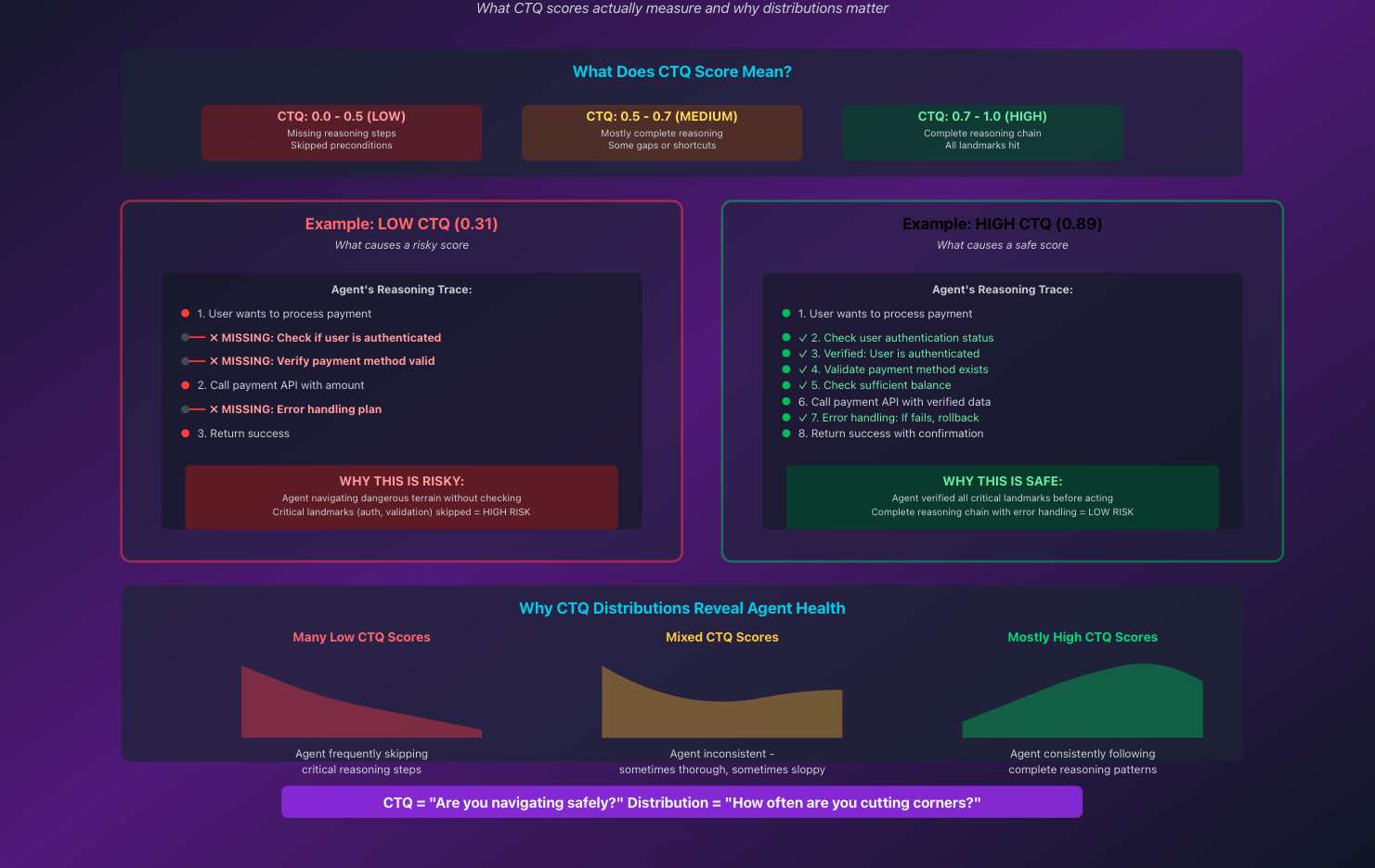
How CTQ scoring works and adapts governance
The Cognitive Trace Quality (CTQ) score is a 0–1 metric that measures reasoning quality, safety, and completeness in real-time. But the real power isn't in individual scores—it's in CTQ distributions.
📊 Why Distributions Matter More Than Thresholds
A single CTQ score tells you about one moment. The distribution tells you about the system's behavior over time. Is the agent consistently performing well in routine tasks but struggling with edge cases? Is there a slow drift toward lower-quality reasoning? Are certain tool combinations producing unpredictable results?
This is how you move from reactive incident response to proactive reliability management.
3. Steward Agents: Adaptive Management at Scale
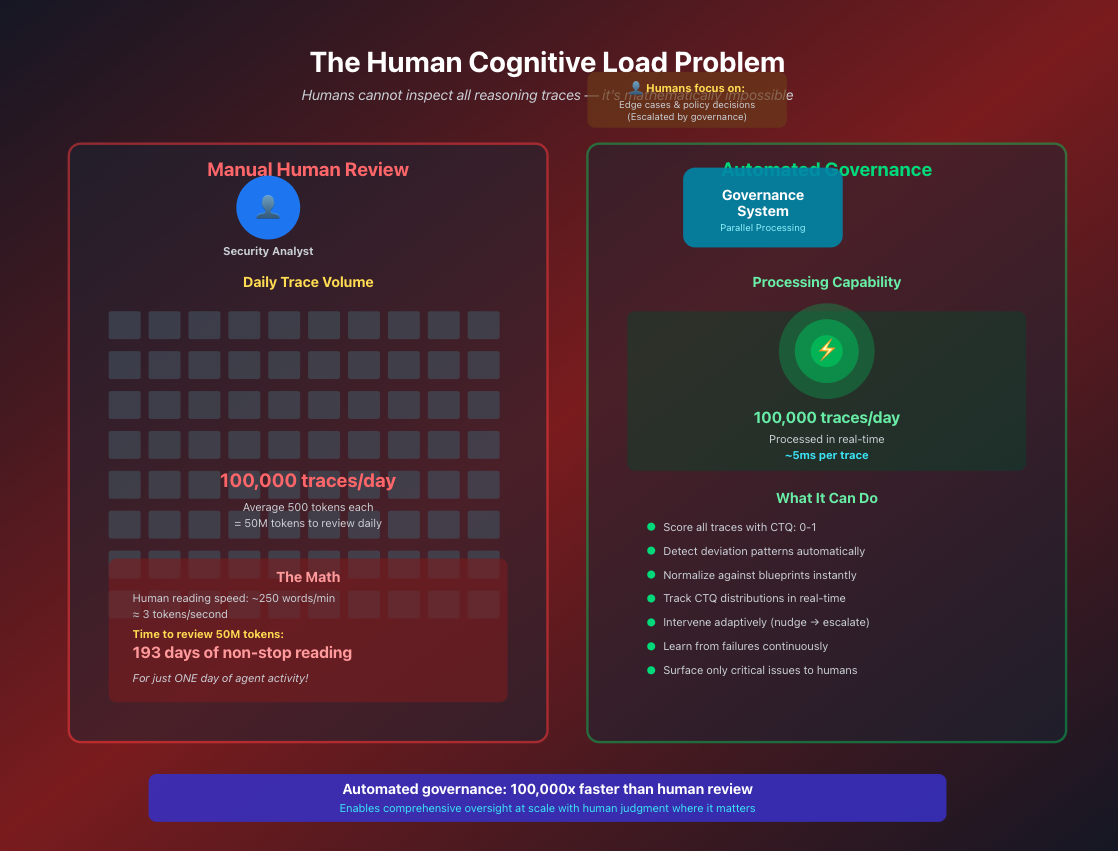
Why human review is mathematically impossible at scale
Human operators cannot manually inspect every reasoning trace. As systems scale, this becomes mathematically impossible—the cognitive load exceeds human bandwidth.
Steward Agents are AI-powered management systems that learn from evidence across thousands of traces to provide adaptive, risk-scaled oversight.
Variable Resolution
Light-touch monitoring for routine operations, deep analysis for difficult terrain.
Graded Interventions
Nudge → flag → block → escalate (not binary pass/fail).
Continuous Learning
Every failure strengthens the system's intelligence.
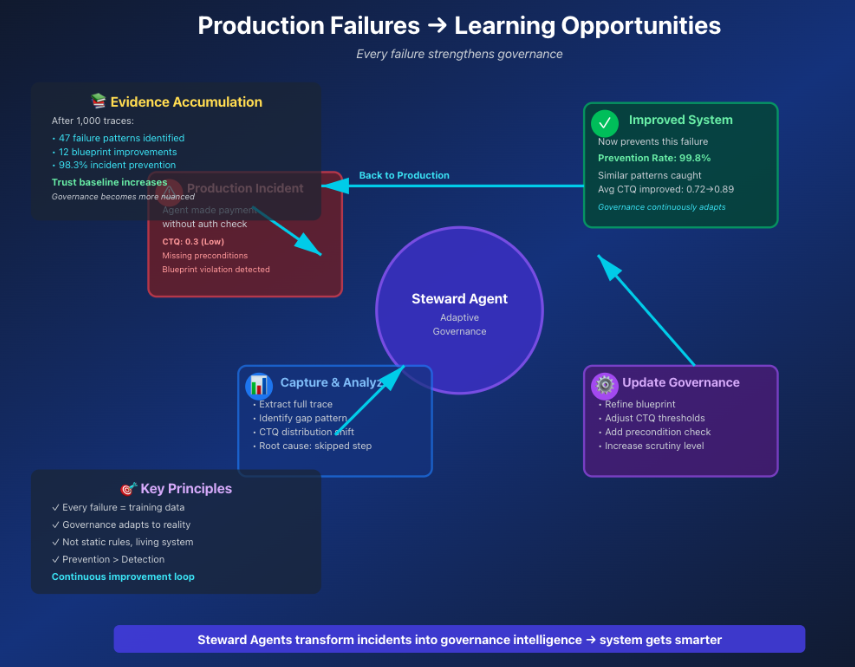
How production failures become learning opportunities
4. Service Integrity Agreements (SIA)

SIAs define operational contracts between agents and systems
Agents need clear operational contracts—not just what tools they can use, but under what constraints they must operate.
| MCP Rules | Service Integrity Agreements |
|---|---|
| "What tools exist and how to invoke them" | "The constraints under which you must operate" |
| Tool discovery and invocation | Budget limits, quality requirements, escalation protocols |
| Static capability description | Dynamic trust baselines and adaptive constraints |
5. Trust Baselines: Evidence-Based Autonomy
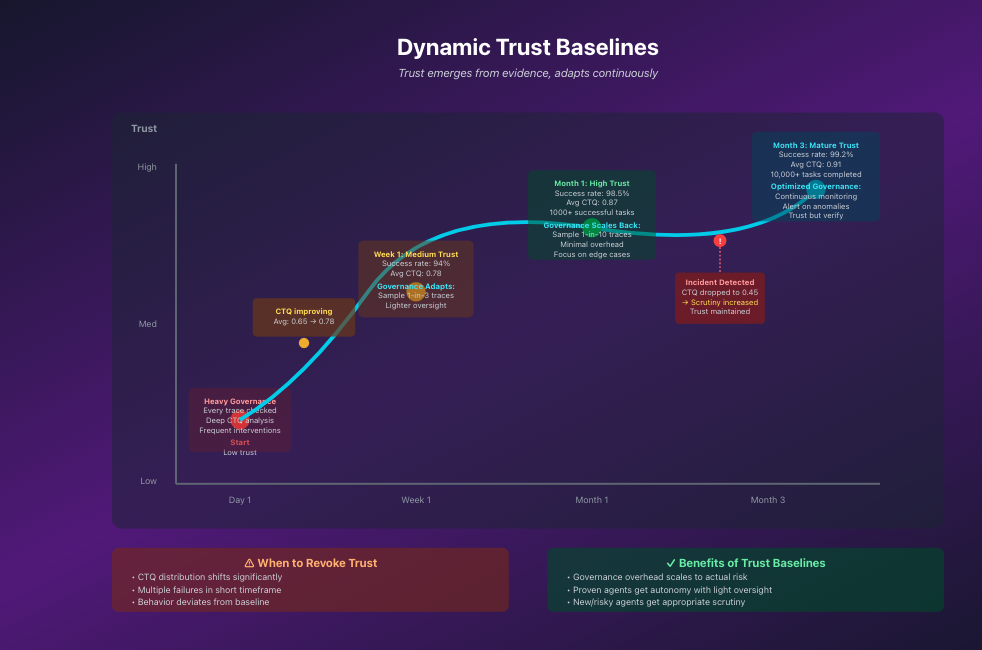
How trust evolves based on historical evidence
Trust isn't binary—it's a spectrum that evolves based on evidence. Agents that consistently demonstrate reliable reasoning earn greater autonomy with lighter oversight. New or risky operations receive appropriate scrutiny.
Practical Implementation: Making Agents Reliable
Managing Tool Calling Reliability
The most common production failure is unreliable tool usage. Here's how to fix it:
Before Tool Calls
- Require agents to reason through Blueprints that encode preconditions.
- Verify the agent's mental model matches the tool's actual capabilities.
- Check that necessary context and state information is available.
During Tool Execution
- Monitor CTQ in real-time to detect reasoning drift.
- Apply variable resolution based on tool risk profiles.
- Enable async evaluation to avoid blocking critical paths.
After Tool Calls
- Capture success/failure patterns in CTQ distributions.
- Update trust baselines for specific tool combinations.
- Feed evidence back to Steward Agents for learning.
CGP is an Agent-to-agent Porotocol Architecture
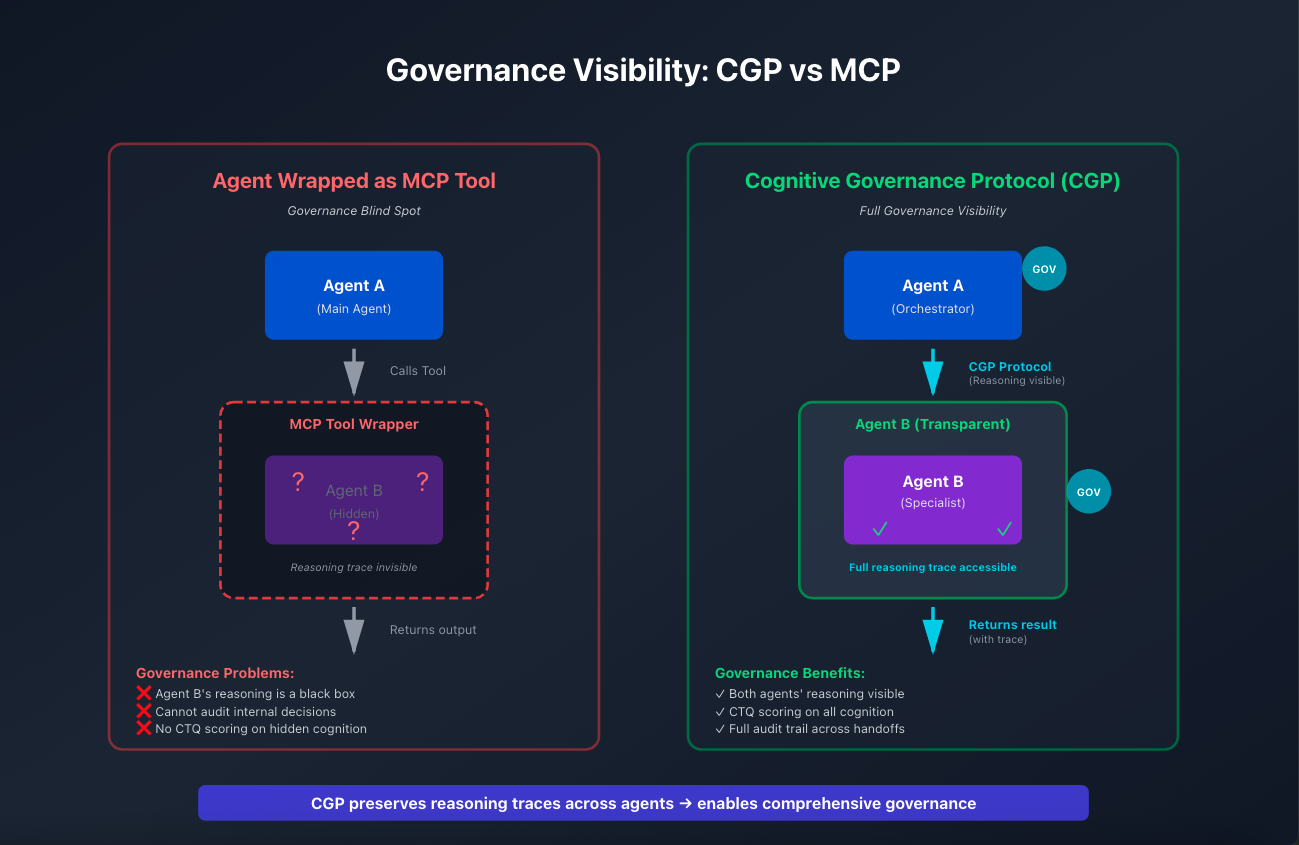
Why CGP preserves reasoning visibility vs. wrapped agents
When agents need to coordinate, architecture choices dramatically affect reliability. Wrapping an agent as an MCP tool loses visibility into its reasoning—it becomes a black box. With A2A architecture, you preserve reasoning traces across both agents, enabling comprehensive governance.
Continuous Evaluation in Production
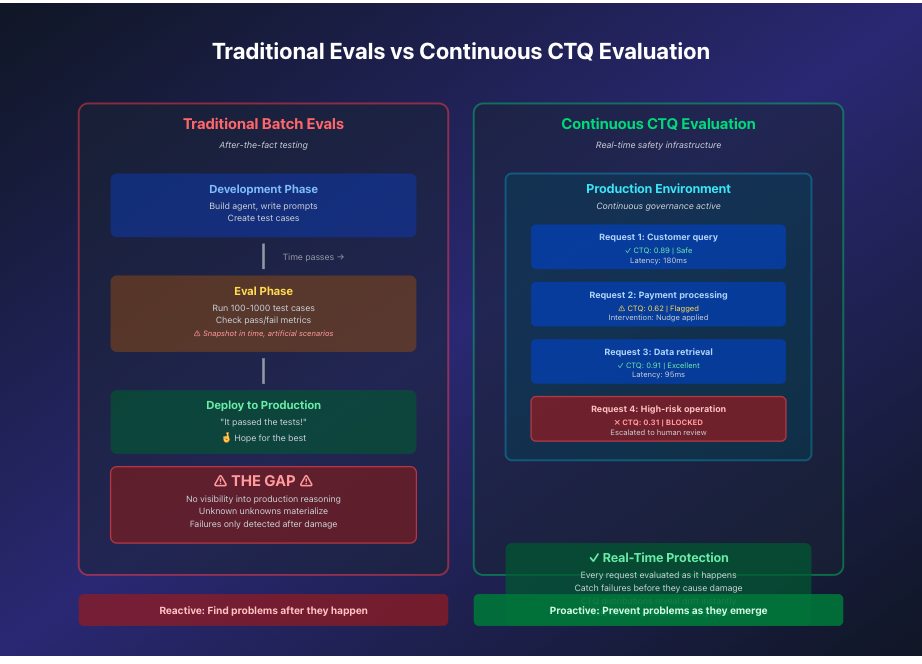
Traditional batch evals vs. continuous CTQ evaluation
Traditional evals are batch processes, disconnected from production reality. Reliable systems need continuous evaluation that transforms assessment from a testing activity into runtime infrastructure.
Complete System Architecture
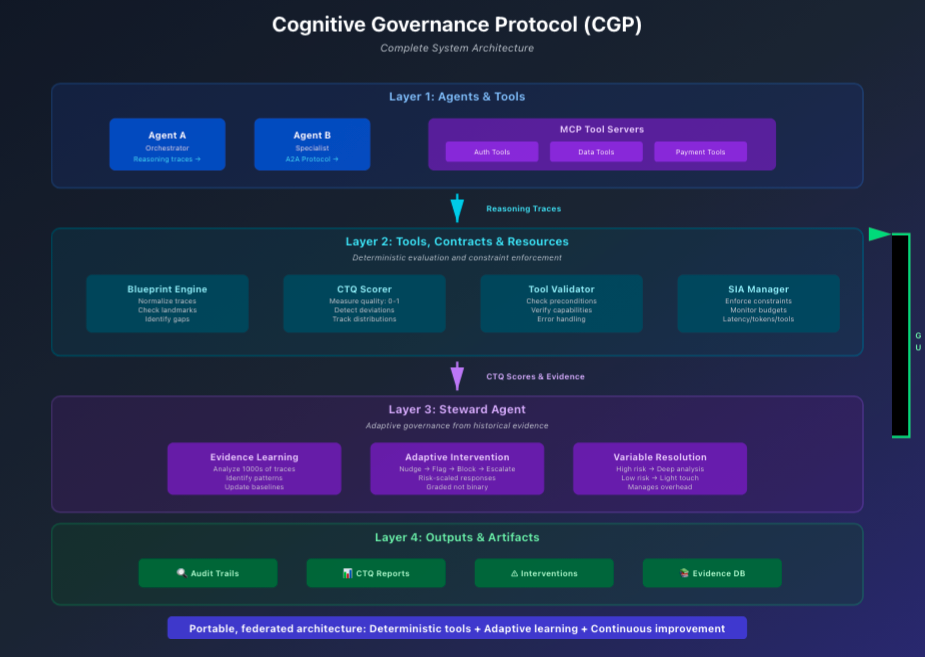
The Cognitive Governance Protocol: complete system architecture
Federated Design for Enterprise Scale

Federated governance architecture with privacy by design
Our architecture is federated by design—no single Steward Agent holds too much power. As we move toward multi-agent environments, we’re integrating privacy-preserving technology so governance can operate without exposing sensitive traces.
The Governance Loop
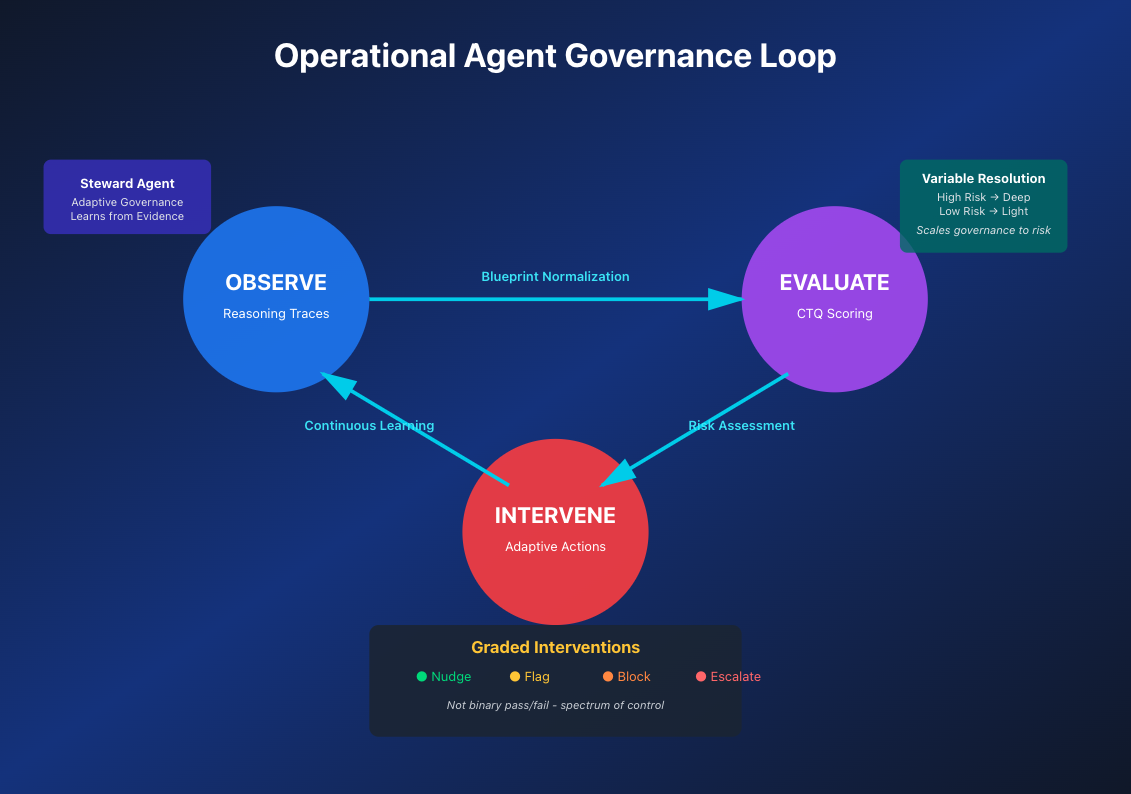
The continuous Observe → Evaluate → Intervene loop
From Theory to Practice: What This Enables
Organizations building reliable agent infrastructure can:
- Deploy agents with confidence knowing reasoning is visible and measurable.
- Scale autonomy safely by adapting management intensity to risk.
- Debug production failures by reconstructing the reasoning that led to incidents.
- Establish trust baselines using historical evidence, not hopes.
- Coordinate multi-agent systems with preserved visibility across handoffs.
- Meet operational constraints around latency, tokens, and costs.
- Learn continuously from every trace, improving reliability over time.
🎯 Most Importantly
You can give agents the autonomy they need to be useful while maintaining the control you need to be safe.
The Path Forward
The agentic systems being built today will soon be critical infrastructure. As agents handle customer interactions, financial transactions, healthcare decisions, and supply chain operations, reliability isn't optional—it's existential.
The question isn't whether to build reliability infrastructure. It's whether to build it as an afterthought or as a first-class layer designed specifically for how agents fail in production.
We're choosing the latter: building Operational Agent Reliability from first principles, informed by real production failures, designed for the complex multi-agent future we're heading toward.
This isn't about restricting what agents can do. It's about making sure they can do what they do safely, measurably, and at scale.
Because the map your agent is using matters just as much as where it's trying to go.
Key Takeaways
- Agents fail in their reasoning processes, not just their outputs—you need visibility into how they think, not just what they do.
- Blueprints provide the terrain map that keeps agents from navigating with missing bridges or faulty assumptions.
- CTQ distributions reveal reliability patterns that single scores or thresholds miss entirely.
- Steward Agents enable adaptive management that scales to complexity while minimizing overhead.
- Variable resolution is essential—uniform governance creates uniform bottlenecks.
- As an A2A architecture, CGP preserves reasoning visibility across agent coordination, enabling reliable multi-agent systems.
- Continuous evaluation in production catches failures before they become incidents.
- Reliability infrastructure should be invisible for safe operations, visible only when it matters.