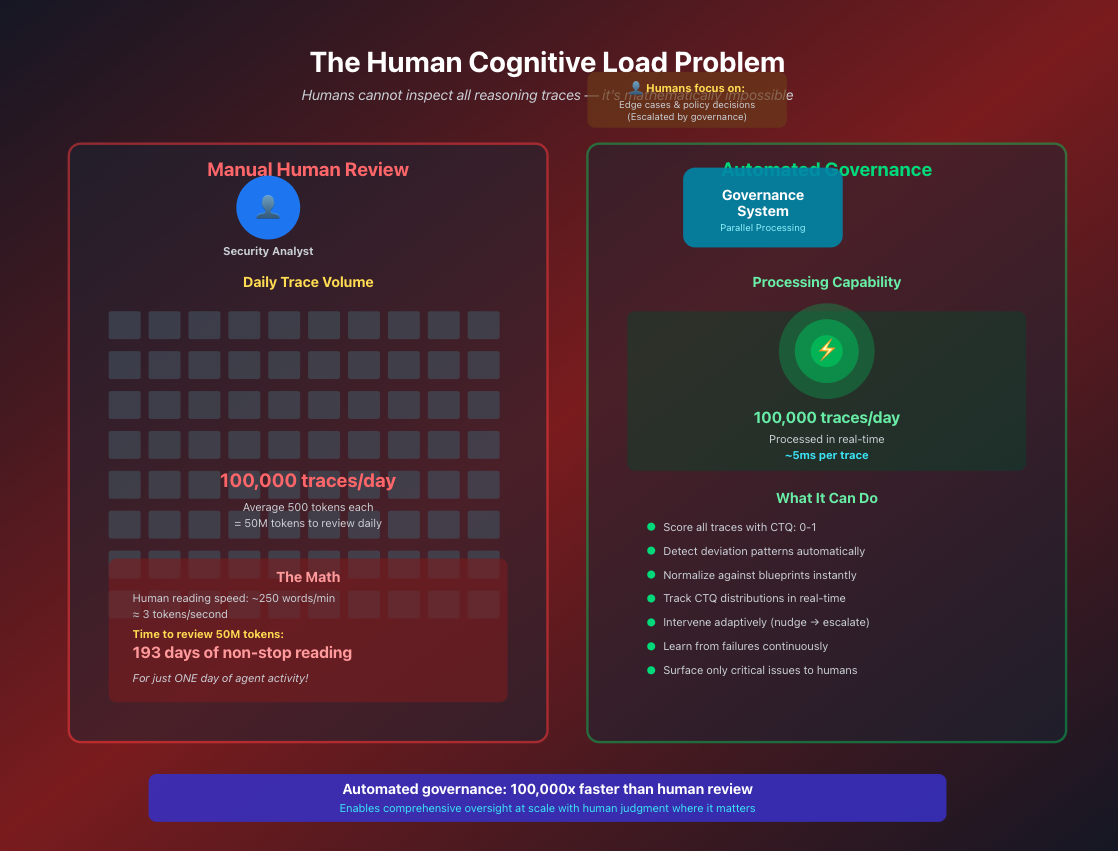
Govern Reasoning by Defining the Terrain
Agents navigate the world using internal mental maps. Blueprints ensure those maps match your real operational topography.
Every agent, when it acts in the world, is operating on a mental map — a topography the model constructs about what matters, what is risky, what must be checked, and how tools should be used. But that map is fragile, incomplete, and sometimes wrong.
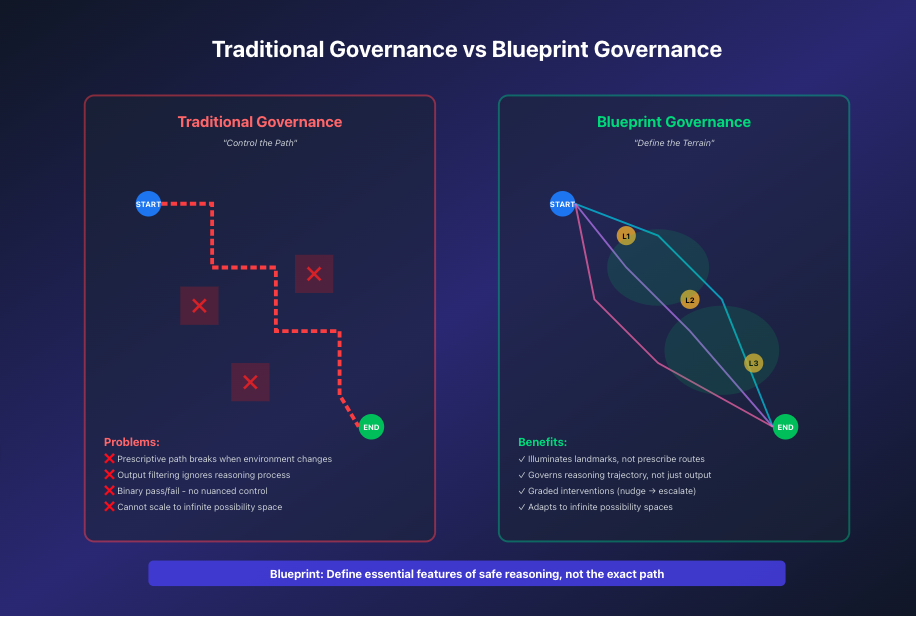
MeaningStack provides enterprise‑grade Blueprints that define the checkpoints that legally matter, the comparisons that must be made, the steps that cannot be skipped, and the relationships that must hold. Blueprints don’t prescribe exact routes — they illuminate the landmarks of safe reasoning so agents can act autonomously inside clear boundaries.